DeepSeek: Revolution in der KI oder nur technischer Hype? – Eine Einschätzung des NAIS-Teams

Die KI-Welt blickt gespannt auf ein neues Startup aus China namens DeepSeek, das mit beeindruckenden Zahlen und einem ungewöhnlichen Geschäftsmodell auf sich aufmerksam macht. Als NAIS (Nordic AI Solutions) möchten wir die wesentlichen Punkte aus technischer Perspektive beleuchten und hinterfragen, was hinter den hohen Erwartungen und den vergleichsweise niedrigen Kosten steckt.
DeepSeek: Ein neues Modell im Rennen
DeepSeek behauptet, ein KI-Modell entwickelt zu haben, das in puncto Leistungsfähigkeit mit GPT-4 vergleichbar ist – und das zu einem Bruchteil der Kosten. Während GPT-4 Schätzungen zufolge über 600 Millionen US-Dollar gekostet hat, wirbt DeepSeek mit 6 Millionen US-Dollar für die Basismodell-Entwicklung. Zusätzlich sind niedrige Inferenzkosten von unter 4 US-Dollar pro Million Tokens im Gespräch, verglichen mit etwa 100 US-Dollar pro Million Tokens bei OpenAI.
Vorteile laut DeepSeek
- Kosteneffizienz: Sowohl in der Entwicklung als auch beim Betrieb sollen die Kosten deutlich geringer sein.
- Offene Lizenzierung: DeepSeek bietet nach eigenen Angaben ein offen zugängliches und permissiv lizenziertes Modell (R1), was eine breite Weiterentwicklung ermöglichen könnte.
Technische Hintergründe statt Schlagzeilen
Ein zentraler Unterschied zwischen DeepSeek und GPT-4 liegt in der Trainingsmethodik. DeepSeek V3 soll teilweise auf Distillation bestehender US-Modelle basieren, was das Training vereinfacht und beschleunigt. Dieser Ansatz nutzt bereits vorhandenes Wissen („Teacher-Student-Prinzip“) und kann die Kosten deutlich reduzieren.
Wichtige Aspekte:
Basismodell vs. finales Modell: Die oft genannten 6 Millionen US-Dollar beziehen sich vermutlich auf das Basismodell (DeepSeek V3). Die finale Version, DeepSeek R1, durchlief noch eine zusätzliche RL-Phase (Reinforcement Learning), die deutlich aufwendiger sein kann.
Reinforcement Learning mit GRPO: DeepSeek R1 nutzt eine skalierte Implementierung von GRPO (Generalized Policy Optimization), um die Qualität der Antworten zu verbessern. Dieser Ansatz erfordert erheblich mehr Rechen- und Personalkosten als ein reines Basismodell-Training.
Aus unserer Sicht ist es daher wichtig, die genannten Kosten kritisch zu hinterfragen und zu schauen, wie sich Basismodell und finale Version unterscheiden.
Algorithmische Grundlagen: OpenAI-o1 vs. DeepSeek-R1
OpenAI-o1: Chain-of-Thought at Scale
- Inference-Time CoT:
OpenAI-o1 setzt auf das Prinzip, das Modell explizit zu einer schrittweisen Argumentation zu „erziehen“. So können umfassendere und präzisere Lösungen entstehen, ohne bei jedem neuen Anwendungsfall komplett neu zu trainieren. - Mischung aus Supervised Learning und Reinforcement Signals:
Obwohl die genauen Trainingsmethoden nicht öffentlich sind, soll OpenAI-o1 großflächig mit Chain-of-Thought-Daten und Feedback-Signalen (z. B. RLHF) trainiert worden sein. - Refinement-Mechanismen:
Varianten von OpenAI-o1 nutzen Self-Verification-Heuristiken, um die generierten Lösungen auf Korrektheit und Vollständigkeit zu prüfen.
DeepSeek-R1: Reinforcement Learning als Kern
DeepSeek-R1 verfolgt einen deutlich anderen Ansatz, bei dem Reinforcement Learning (RL) im Vordergrund steht. Laut bereitgestellten Informationen existiert ein zweistufiges Verfahren:
- DeepSeek-R1-Zero
- Cold-Start ohne Supervised Fine-Tuning (SFT): Reinforcement Learning direkt aus einem Basis-LLM, ohne anfängliches Überwachen der Feintuning-Phase.
- Rule-Based Rewards: Belohnungen für Korrektheit (z. B. mathematische Genauigkeit) und strukturierte „Chain-of-Thought“-Formate.
- Ergebnis: Beachtliche Reasoning-Leistung, gelegentlich jedoch ungewöhnliche Effekte (z. B. Sprachen-Mix).
- DeepSeek-R1
- Cold-Start SFT for Readability: Ein hochwertiges Seed-Dataset sorgt für eine natürlichere Chain-of-Thought-Struktur.
- Large-Scale RL: Ausgiebiges Reinforcement Learning mit umfangreichem Feedback zur Korrektheit und sprachlichen Konsistenz.
- Post-RL SFT: Zusätzliches Supervised Data für Bereiche wie Creative Writing, Factual QA und Self-Cognition.
- Final RL: Ein letzter RL-Schritt, um die Balance zwischen Reasoning und Sprachkompetenz zu optimieren.
Fazit: DeepSeek-R1 setzt sehr konsequent auf iterative Reinforcement-Learning-Strategien für reasoning-intensive Aufgaben und unterscheidet sich damit fundamental von konventionellen LLMs, die vorwiegend auf großes Supervised Learning bauen.
Subventionierte Inferenzkosten: Technische Möglichkeiten
DeepSeek wird häufig für seine extrem niedrigen Betriebskosten gelobt. Laut Unternehmensangaben liegen diese bei unter 4 US-Dollar pro Million Tokens. Gerade für Large Language Models (LLMs) sind solche Kosten meist schwer erreichbar, es sei denn:
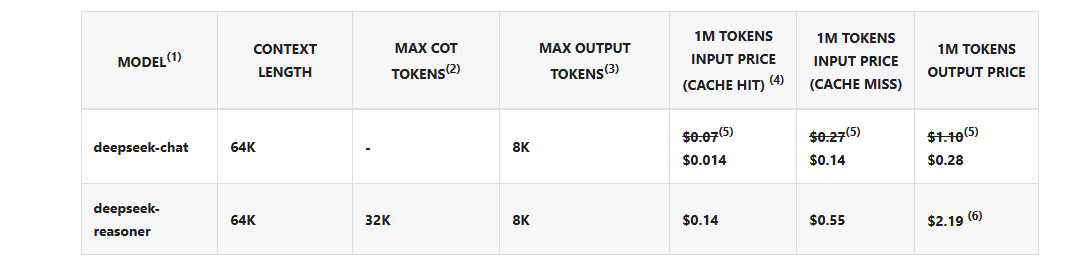
Was passiert hier?
Spezialisierte Hardware: Möglicherweise nutzt DeepSeek eine Vielzahl von GPUs, TPUs oder andere Spezialprozessoren, die durch Massenkäufe oder besondere Partnerschaften günstiger bereitgestellt werden.
Optimierte Modellarchitektur: Eine schlankere Architektur oder distillierte Modelle können die Inferenz effizienter machen.
Cluster-Management und Software-Stack: Auch intelligente Lastverteilung oder proprietäre Optimierungsverfahren können Kosten reduzieren.
Ganz ohne größere Investitionen bleibt jedoch fraglich, ob die angegebene Zahl für alle Anwendungsfälle realistisch ist – oder ob zusätzliche finanzielle Unterstützung im Hintergrund eine Rolle spielt.
Markt-Disruption durch DeepSeek?
DeepSeek hat den globalen Markt laut einiger Berichte grundlegend verändert, indem es bewiesen haben soll, dass hochperformante Modelle mit deutlich geringeren Kosten und auf weniger leistungsfähiger Hardware trainiert werden können.
- Hardware-Aspekt:
DeepSeek trainiert angeblich erfolgreich auf H800 GPUs – einer modifizierten Version der H100, die wegen US-Exportbeschränkungen adaptierte Leistungsparameter besitzt. - Effizienz vs. Profitmarge:
Dieser Erfolg könnte das Geschäftsmodell von Hardwareanbietern wie NVIDIA unter Druck setzen, da DeepSeek eine vergleichbare Performance mit kostengünstigerer Hardware erzielt. - Auswirkungen auf Investitionen:
Analysten befürchten, dass die massiven Investitionen von Tech-Giganten in teure Cloud-Infrastruktur (insbesondere mit H100 GPUs) teilweise überdimensioniert sein könnten, wenn sich DeepSeeks Ansatz bestätigt.
Ob sich dieser Trend langfristig durchsetzen wird, bleibt abzuwarten. Klar ist jedoch, dass eine mögliche Neubewertung von Hard- und Softwarekosten stattfindet – was zu einer Umstrukturierung in der gesamten KI-Industrie führen kann.
Der politische Kontext: Kurz notiert
Obwohl DeepSeek in den Medien häufig mit geopolitischen und wirtschaftlichen Faktoren in Verbindung gebracht wird, möchten wir als NAIS-Team den technischen Kern in den Vordergrund stellen. Internationale Konkurrenz und mögliche Subventionen sind in der KI-Welt keine Seltenheit. Entscheidend ist jedoch, ob DeepSeek langfristig technisch überzeugen kann und nicht nur auf kurzfristige Publicity setzt.
Was bedeutet DeepSeek für die KI-Branche?
- 1. Neue Konkurrenz belebt das Geschäft
- Bisher dominieren vor allem US-Unternehmen wie OpenAI und Google mit ihren LLMs den Markt. DeepSeek könnte frischen Wind in die Branche bringen, wenn es gelingt, eine hohe Leistung zu niedrigen Kosten bereitzustellen.
- 2. Mehr Offenheit
- DeepSeek wirbt mit einer Open-Source-Herangehensweise, was die Weiterentwicklung und Anpassung des Modells beschleunigen könnte. Community-getriebene Projekte profitieren von schnellerem Feedback und vielseitigen Anwendungsfällen.
- 3. Fokus auf Effizienz
- Der vermeintlich niedrige Ressourcenverbrauch von DeepSeek rückt das Thema Effizienz in den Mittelpunkt. Sowohl Entwicklungsteams als auch Unternehmen sind zunehmend daran interessiert, Energie und Kosten zu sparen. Modelle, die weniger Rechenleistung erfordern, könnten hier eine Vorreiterrolle einnehmen.
Fazit: Technisch interessant, aber mit offenem Ausgang
Als NAIS-Team sehen wir in DeepSeek einen interessanten neuen Mitbewerber im KI-Markt, der einige etablierte Prozesse hinterfragt und mit viel Selbstbewusstsein einen anderen Weg einschlägt. Wir empfehlen jedoch, bei den genannten Kosten und Leistungsversprechen genauer hinzuschauen und zu prüfen, welche Rahmenbedingungen tatsächlich vorliegen.
Eines steht fest: Neue Player wie DeepSeek tragen dazu bei, dass Innovationen im KI-Sektor schneller vorangetrieben und Technologien effizienter gestaltet werden. Ob DeepSeek sich langfristig durchsetzt oder nur kurzfristig für Furore sorgt, wird die Praxis zeigen. In jedem Fall bedeutet mehr Vielfalt in der Branche stets mehr Chancen – und davon können letztendlich alle profitieren.
Deepseek-Modelle, darunter Deepseek V3 oder Deepseek R1 können wir selbstverständlich über Azure in Lösungen integrieren und somit auch den notwendigen Datenschutz sicherstellen 🙌
Wir unterstützen Sie dabei, Ihre Arbeitsprozesse mit KI zu unterstützen und Zeit für die wirklich wichtigen Themen zu gewinnen
– Nordic AI Solutions

Interesse an einem Prompting-Workshop?
Möchtest du einen vollumfänglichen Prompting-Workshop durchführen? Kontaktiere uns für eine persönliche Beratung oder eine kostenlose Vorschau.
Technologie ist nur dann erfolgreich, wenn sie von den Menschen verstanden und akzeptiert wird. Wir helfen Unternehmen dabei, ihre Teams im sicheren Umgang mit KI-Tools zu schulen und Vertrauen in die neuen Technologien zu gewinnen
– Nordic AI Solutions
Beratungsgespräch anfragen
Ein Gespräch mit uns lohnt sich eigentlich immer! Und zwar auch, wenn Sie noch nicht wissen, welche KI-Anwendungen für Sie oder Ihre Kunden sinnvoll und wie sie zu realisieren sind: Gerade solche Fragen lassen sich schließlich ohne fundierte IT-Kompetenz kaum schlüssig beantworten. Wir beraten Sie gern – und freuen uns riesig über Ihr Interesse an unserem Lieblingsthema.